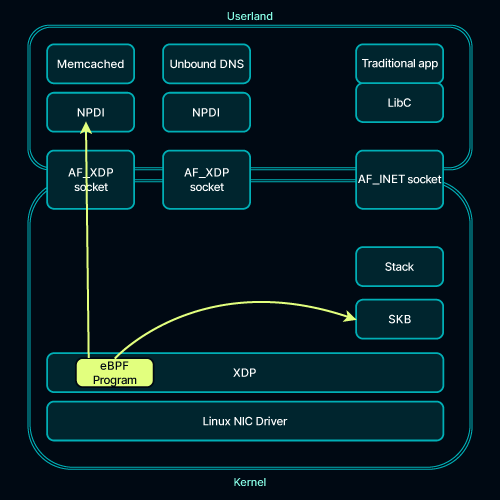
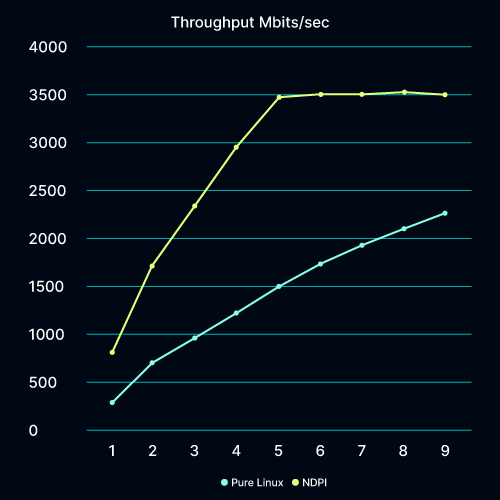
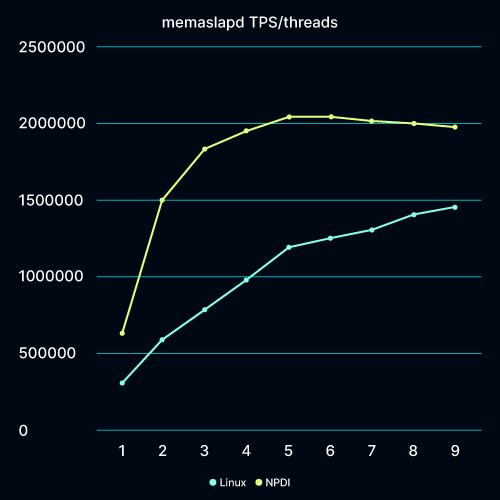
NPDI does not require:
- Any modifications to the installed kernel
- Recompilation of the application
- Reconfiguration of the system.
If you want to rollback – done instantly, you unregister our eBPF program, unload kernel module, stop using our system and switch back to the old ways. Safe and effortless.